








https://getcomposer.org/doc/01-basic-usage.md
https://php-de.github.io/jumpto/composer/#composer-installation
https://linuxize.com/post/how-to-install-and-use-composer-on-ubuntu-18-04/

https://getcomposer.org/doc/01-basic-usage.md
https://php-de.github.io/jumpto/composer/#composer-installation
https://linuxize.com/post/how-to-install-and-use-composer-on-ubuntu-18-04/
Let’s assume you have a folder structure for your project like this (directory names are bold) and it is a project thats exposing port 80:
(project root) / ├── index.html ├── script.js ├── style.css └── Dockerfile
I would encourage you to put all your project related stuff to a subfolder (it is easier to keep track of what folder belongs to which container) so it looks like this:
(project root) /
└── Super cool project /
├── index.html
├── script.js
├── style.css
└── Dockerfile
A very basic way to „convert“ (or more integrate) your Dockerfile into a docker-compose.yml is the following:
Create a file called „docker-compose.yml“ in your project’s root folder:
(project root) / ├── Super cool project / │ ├── index.html │ ├── script.js │ ├── style.css │ └── Dockerfile └── docker-compose.yml
In your docker-compose.yml you now put in the following content:
version: "3.8"
services:
super-cool-container:
build: "./Super cool project"
ports:
- 80:80
Now you are already good to go! Just go to the folder where your docker-compose.yml is located and run the following command to start all the containers listed in this file as a service:
docker compose up -d
To shut down all the containers just run:
docker compose down
Now you’re good to go! If your container is started with more parameters etc. you can look up the documentation for docker compose and have a look on how you have to edit your docker compose file to include those parameters.
https://www.loc.gov/standards/sru/cql/
https://de.wikipedia.org/wiki/Contextual_Query_Language
CQL, the Contextual Query Language, is a formal language for representing queries to information retrieval systems such as web indexes, bibliographic catalogs and museum collection information. The design objective is that queries be human readable and writable, and that the language be intuitive while maintaining the expressiveness of more complex languages.
Traditionally, query languages have fallen into two camps: Powerful, expressive languages, not easily readable nor writable by non-experts (e.g. SQL, PQF, and XQuery);or simple and intuitive languages not powerful enough to express complex concepts (e.g. CCL and google). CQL tries to combine simplicity and intuitiveness of expression for simple, every day queries, with the richness of more expressive languages to accomodate complex concepts when necessary.
http://www.cidoc-crm.org/crmgeo/home-5
CRMgeo is a formal ontology intended to be used as a global schema for integrating spatiotemporal properties of temporal entities and persistent items. Its primary purpose is to provide a schema consistent with the CIDOC CRM to integrate geoinformation using the conceptualizations, formal definitions, encoding standards and topological relations defined by the Open Geospatial Consortium (OGC). In order to do this it links the CIDOC CRM to the OGC standard of GeoSPARQL.
CRMgeo provides a refinement of spatial and temporal classes and properties of the CIDOC CRM. It relates them to the classes, topological relations and encodings provided by GeoSPARQL and thus allows spatiotemporal analysis offered by geoinformation systems based on the semantic distinctions of the CIDOC CRM.
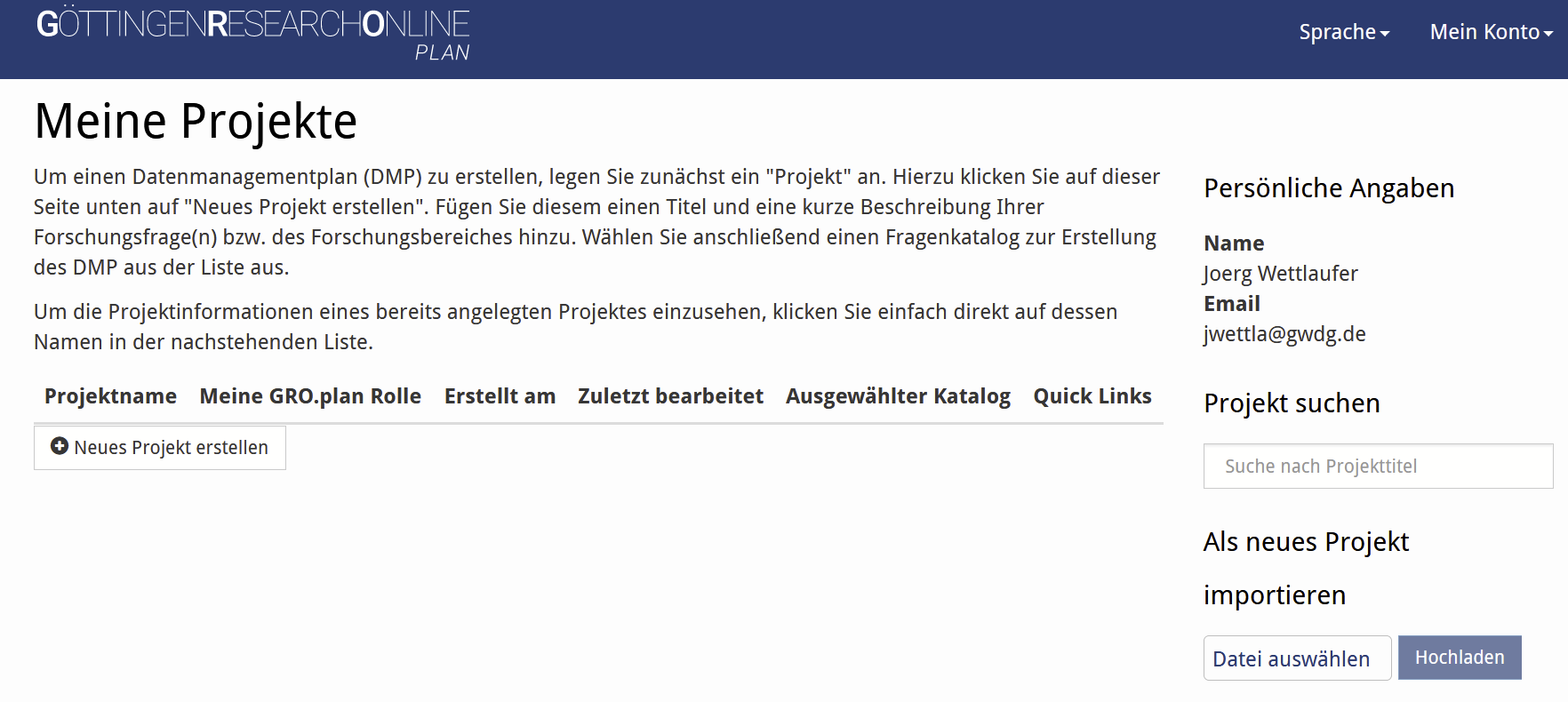
Neuer Dienst im Portal Göttingen Research Online!
GRO.plan steht Ihnen und Ihren Kolleg*innen sowie fortgeschrittenen Studierenden ab sofort zur Verfügung um fragegeleitet Datenmanagementpläne für Ihr nächstes Forschungsprojekt zu erstellen. Ausführlichere Informationen zum Dienst finden Sie auf unserer Webseite unter https://www.eresearch.uni-goettingen.de/services-and-software/gro-plan/.
Den Dienst direkt erreichen Sie hier: http://plan.goettingen-research-online.de/. Probieren Sie es gerne aus.
Introduction: This article aims to provide an overview of designing a Continuous Integration/Continuous Deployment (CI/CD) pipeline in Git. The article highlights the importance of CI/CD pipeline in software development, and explains how it helps to automate and streamline the development process. By designing a CI/CD pipeline in Git, developers can ensure that their code is always up-to-date, tested, and ready for deployment.
Step 1: Setting up Git Repository. The first step is to create a Git repository for the project. Developers can use either GitHub, GitLab or Bitbucket to create a Git repository but this article is based on GitLab. Once the repository is set up, developers can start committing their code to the repository.
Step 2: Setting up CI/CD Pipeline. The second step is to set up a CI/CD pipeline in Git. The pipeline is written in code which is hosted inside the application’s git repository. The whole CI/CD configuration is written in YAML format. The file has to be called “.gitlab-ci.yml” so that gitlab can automatically detect the pipeline code and execute it without any configuration from developer’s side. Now, create a “.gitlab-ci.yml” in the root of the application’s git repository so that gitlab will automatically detect it as application’s pipeline code. The pipeline is designed to automate the build, test and deployment process. The pipeline is triggered every time a new commit is made to the Git repository. The pipeline then automatically builds the code, runs tests and deploys the code to the production environment.
Step 3: Building and Testing. The third step is to build and test the code. Once the code is built, developers can run automated tests to check if the code is working as expected. If the tests fail, the pipeline is stopped, and developers receive an alert. Developers can then fix the code and restart the pipeline.
Step 4: Deploying to Production. The fourth step is to deploy the code to the production environment. Developers can use Kubernetes or Docker to deploy the code. The pipeline deploys the code automatically to the production environment, ensuring that the code is always up-to-date and available to users.
Conclusion: In conclusion, designing a CI/CD pipeline in Git is an essential part of agile development. By automating the build, test, and deployment process, developers can ensure that their code is always up-to-date, tested, and ready for deployment. Setting up a CI/CD pipeline in Git requires careful planning, but it ultimately saves time and increases productivity. With a well-designed pipeline, developers can focus on writing code, while the pipeline takes care of the rest.
https://gepris.dfg.de/gepris/projekt/439948010?context=projekt&task=showDetail&id=439948010&
Die Entwicklung einer digitalen 3D-Viewerinfrastruktur für geschichtswissenschaftliche 3D-Rekonstruktionen soll zum ersten Mal als dauerhaftes Infrastrukturangebot einerseits eine nachhaltige Zugänglichkeit sowie Archivierung von Rohdatensätzen und Metainformationen ermöglichen, andererseits durch die Erzeugung von 3D-Webmodellen aus gängigen Datentypen eine Kollaboration sowie einen Fachdiskurs am virtuellen Modell ermöglichen. Die zu entwickelnde 3D-Viewerinfrastruktur soll somit eine umfassende und nachhaltige geistes- und geschichtswissenschaftliche Objekt- und Raumforschung unter Berücksichtigung interoperabler Dokumentationsstandards, sowie anwendungsbezogener Integration webbasierter, interaktiver 3D-Datenviewer ermöglichen. Dabei sollen folgende Aspekte Berücksichtigung finden:- Speicherung von proprietären 3D-Datensätzen unter Berücksichtigung der Langzeitverfügbarkeit- 3D-Web-Daten-Viewer- Dokumentation von 3D-Daten mittels Meta- und Paradaten, im Folgenden als Metadaten zusammengefasst, in einem standardisierten AustauschformatBetrachtet werden soll der gesamte Publikationsprozess von der Speicherung und Langzeitsicherung der (meist proprietären) 3D-Forschungsdaten, über die automatisierte Bereitstellung von Web-Derivaten in einem den bestehenden DFG-Standards folgenden Austauschformat bis hin zur dezentralen Anzeige dieser Webmodelle im DFG-Viewer und in geeigneten Forschungsumgebungen.
Tool zur Präsentation von Digitalen Editionen auf github:
https://github.com/DiScholEd/pipeline-digital-scholarly-editions
Born from the DAHN project, a technological and scientific collaboration between Inria, Le Mans Université and EHESS, and funded by the French Ministry of Higher Education, Research and Innovation (more information on this project can be found here), the pipeline aims at reaching the following goal: facilitate the digitization of data extracted from archival collections, and their dissemination to the public in the form of digital documents in various formats and/or as an online edition.
This pipeline has been created by Floriane Chiffoleau, under the supervision of Anne Baillot and Laurent Romary, and with the help of Alix Chagué and Manon Ovide.